Multistep instructions, such as recipes and how-to guides, greatly benefit from visual aids,
such
as a series of images that accompany the instruction steps. While Large Language Models
(LLMs) have become adept at generating coherent textual steps, Large Vision/Language
Models (LVLMs) are less capable of generating accompanying image sequences. The most
challenging aspect is that each generated image needs to adhere to the relevant textual step
instruction, as well as be visually consistent with
earlier images in the sequence.
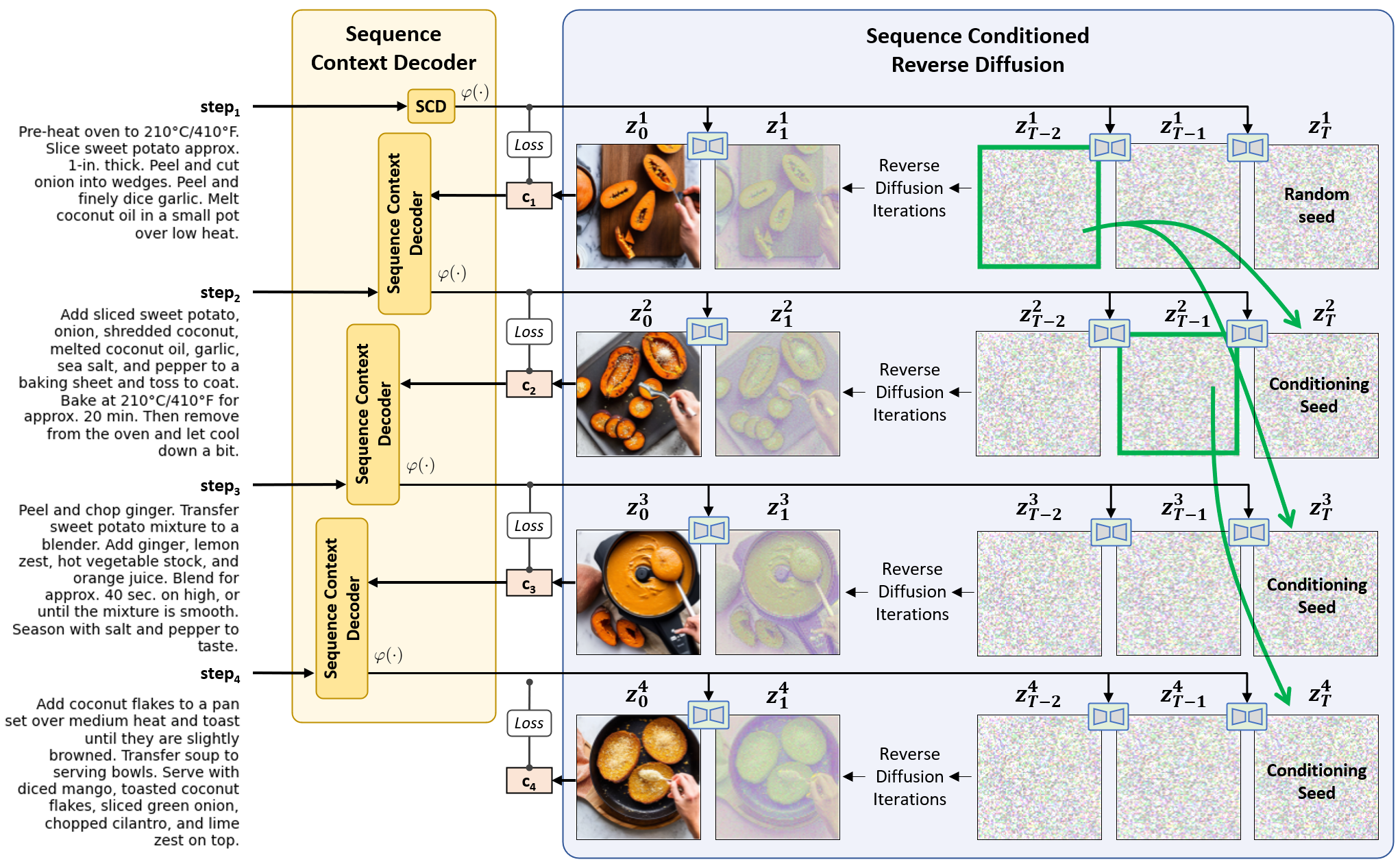
To address this problem, we propose an approach for
generating consistent image sequences,
which integrates a Latent Diffusion Model (LDM) with an LLM to transform the sequence into a
caption to maintain the semantic coherence of the
sequence. In addition, to maintain the visual coherence of the image sequence, we introduce
a copy mechanism to initialise reverse diffusion
processes with a latent vector iteration from a previously generated image from a relevant
step. Both strategies will condition the reverse
diffusion process on the sequence of instruction
steps and tie the contents of the current image
to previous instruction steps and corresponding
images.
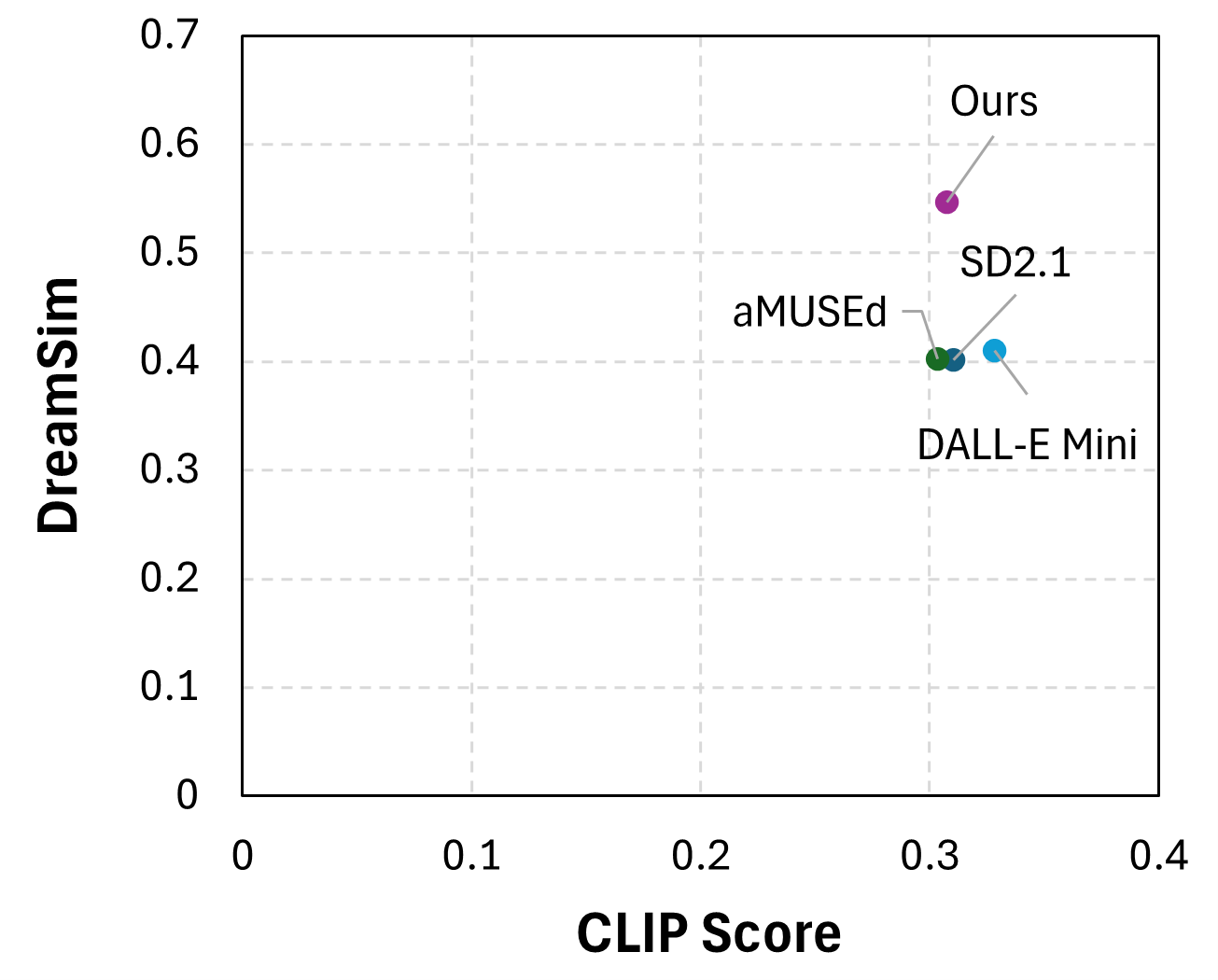
Experiments show that the proposed
approach is preferred by humans in 46.6% of
the cases against 26.6% for the second best
method. In addition, automatic metrics showed
that the proposed method maintains semantic
coherence and visual consistency across the
sequence of visual illustrations.